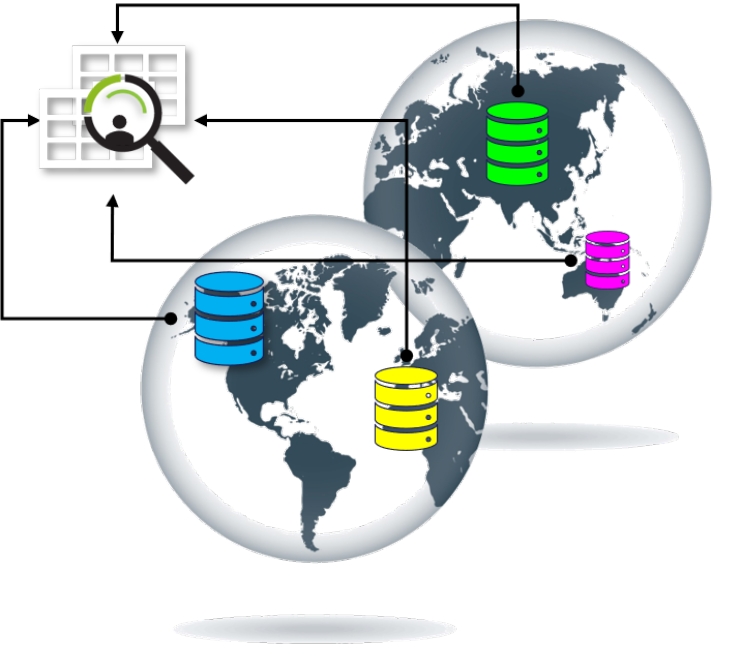







Allows entity resolution in a multilingual environment: “understanding” multilingual entries in their original representation, resolving entries across languages by using a common mathematical denominator. Fincom's ENTITY RESOLUTION TOOLS operate across 40+ different languages in original Alphabets and/or transliterated forms.
Enables accurate data entries comparison by automatically resolving different transliterations, pronunciations, and spelling variations, similar nearby names and ‘name distance’ thresholds.

Anonymizing data entries by converting Names into mathematical codes enables fully anonymized data sharing within and across organizations.

Creating a reliable baseline data-source, ensuring further uninterrupted and efficient data processing. Improving data management, mitigating errors and overcoming ambiguities caused by incorporating data from various data formats and/or languages.



