
First of all, what is “algorithmic bias? In her article, “Reconciling legal and technical approaches to algorithmic bias”, Alice Xiang refers to “statistical models trained on data”, when speaking about “algorithms”. However, this definition more appropriately describes the ML rule-based models and the AI systems based on these models. In consideration of the fact that “algorithm” is a broader concept, encompassing both artificial intelligence and machine learning technologies, as well as pure mathematical systems, and since this article explores both “sides” of the algorithmic coin, it is necessary to differentiate between AI/ML algorithms and mathematical algorithms, detached from everything except numbers and formulas. Therefore, for the sake of precision we will call it “AI bias.”
In addition, it is necessary to agree upon one important point before we can move forward in exploring the problem of AI bias, which is that “rule-based statistical models trained on data” (i.e., AI/ML algorithms) can (and usually are) biased, because:
- AI/ML Algorithms rely on rules created by humans, and humans cannot be guaranteed from unintentional or intentional bias;
- Training data may (and usually is) derived from historical data accumulated over many years or decades. The society has changed considerably during these years, and what is now considered a bias was once considered the norm. Consequently, any AI or ML algorithm trained on such data will also be biased.
Unlike AI rule-based algorithms, mathematical algorithms are not biased, unless they depend on data generated by rule-based algorithms.
It becomes quite clear, therefore, that relying solely on AI/ML systems in decision-making may produce considerable discrimination issues. However, processing large volumes of data without technological assistance is either impossible, or at the very least extremely inconvenient. Also, it does not resolve the issue of bias, since organizations cannot ensure that staff decisions are 100% fair. All this is on top of the problems of human error and the inability to process large amounts of information in real time.
David Skanderson, Vice President of CRA1, speaks about risks involved in decision making based on ML/AI engines. He notices, among other things, that the risk of “unknowing and unintentional discrimination is an increasing concern with the increased application of complex machine learning and so-called artificial or automated intelligence (AI) models to ever-expanding sets of available data to make decisions about consumers…”
Moreover, he argues that there is a risk that “a model’s use will result in the violation of laws or regulations (such as prohibitions on discrimination), or will cause costly reputational harm.”
In addition, due to strict AML/CFT laws and regulations, financial institutions need to take proactive measures to combat financial crime in general, and Money Laundering and Terrorism Financing in particular.
But how is it possible to succeed in both? The question is, how can we avoid ‘AI bias’ while adhering to the AML/CFT regulations?
Phonetic Fingerprint technology developed by FinCom.co ensures conformity, prevents financial crimes, and saves millions of dollars for banks and other financial institutions.
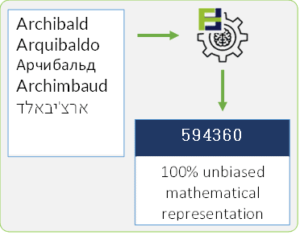
Phonetic Fingerprint is a mathematical representation of a name (personal or company) based on the pronunciation and the phonemes. In addition to using automated real-time technology, and over 48 mathematical algorithms, the system tracks phonemes across 40 different languages, transliterations, and spelling variations. This allows for accurate name matching, free of “AI bias.” and applicable for both simple and structured names. In addition, it greatly reduces the rate of False Positives and virtually eliminates False Negatives.
Find more information on Phonetic Fingerprint Technology and Solutions
[1] a leading global consulting firm in the sphere of economics, finance, and strategy to major law firms, corporations, accounting firms, and governments around world



